|
|
 |
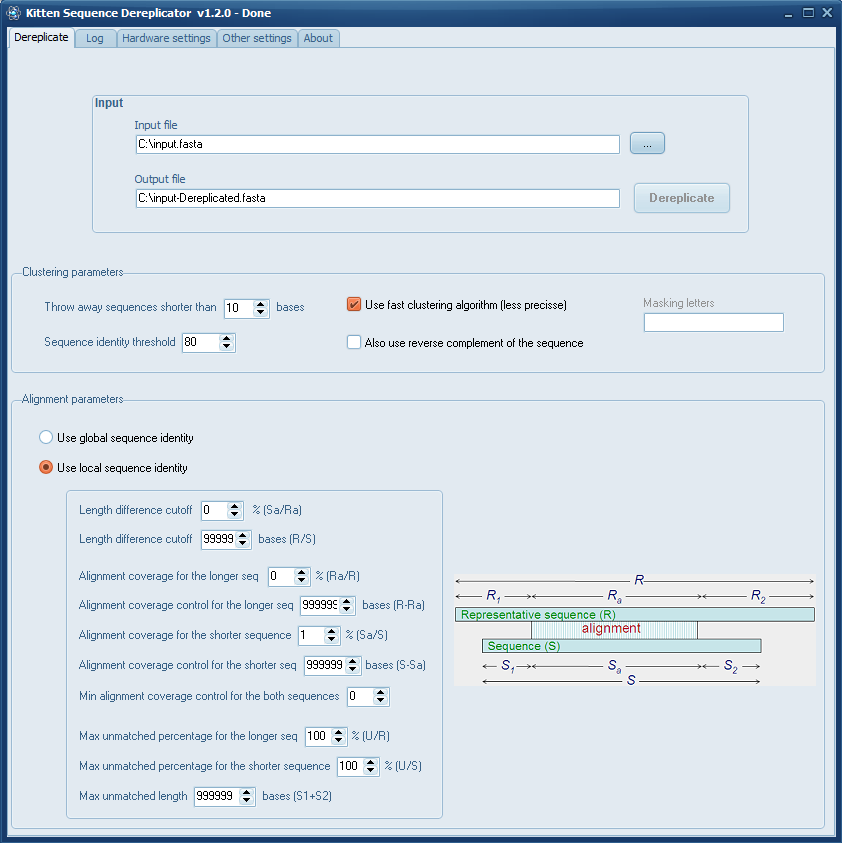
Fasta Sequence Dereplicator The way bioinformatics programs should be...
Fasta Sequence Dereplicator is a Windows tool that allows you to dereplicate your sequences via sequence clustering. Fasta Sequence Dereplicator is a graphic interface on top of CD Hit Est program.
About CD-Hit Sequence Dereplicator
CD-HIT is a bioinformatics tool for clustering and comparing protein or nucleotide sequences (FASTA). CD-HIT was originally developed by Dr. Weizhong Li. CD-HIT uses a fast clustering algorithm and can handle extremely large databases. CD-HIT significantly reduces the efforts in many sequence analysis tasks and aids in understanding the data structure and correct the bias within a dataset. The CD-HIT package includes many other tools but for the moment we offer a graphic interface only for CD-Hit Est:
How sequence dereplication works?
A sequence dereplication tool will:
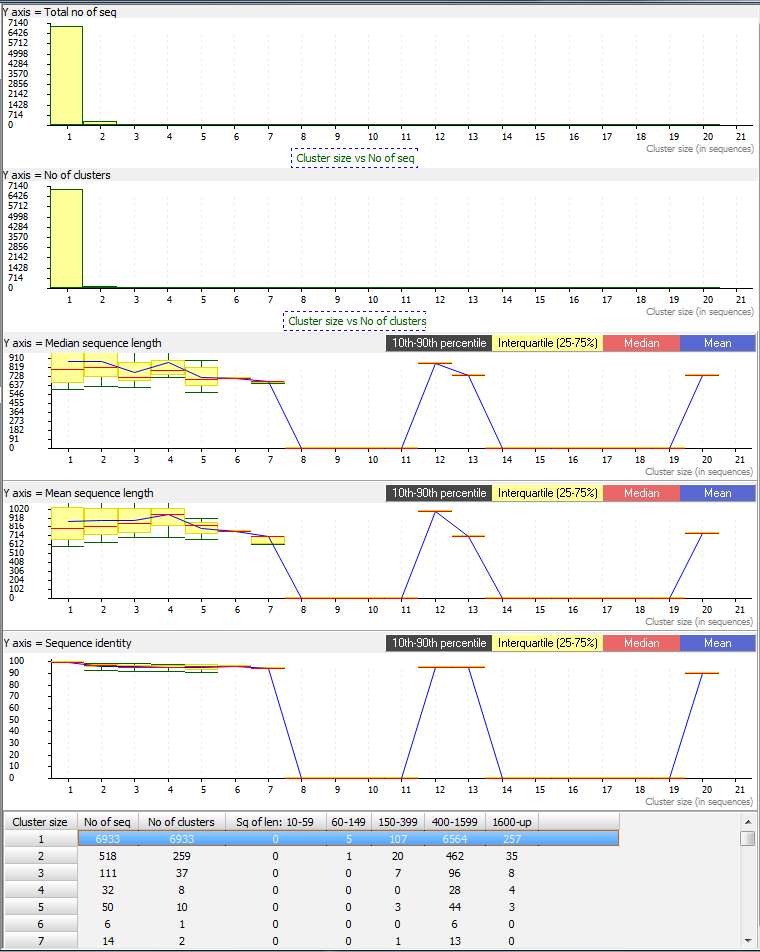
This way, duplicate sequences are removed from a library. Our Fasta Sequence Dereplicator program simplifies the dereplication of 16S rDNA sequence libraries and prepares the raw sequences for subsequent analyses. The input is a protein dataset in fasta format and the output are two files: a fasta file of representative sequences and a text file of list of clusters.
|
||||||||||||
|
|
Requirements
Portability
Fasta Sequence Dereplicator is really small so you can easily copy it on a floppy disk or USB flash stick and take it with you or send it to your colleagues via email. |
||||||||||||
Plans for next version
This tool is
|
|||||||||||||